

Data 2024, 9(5), 67; https://doi.org/10.3390/data9050067 (registering DOI) - 11 May 2024
Abstract
►
Show Figures
The evaluation and ranking of educational institutions are of paramount importance to a wide range of stakeholders, including students, faculty members, funding organizations, and the institutions themselves. Traditional ranking systems, such as those provided by QS, ARWU, and THE, have offered valuable insights
[...] Read more.
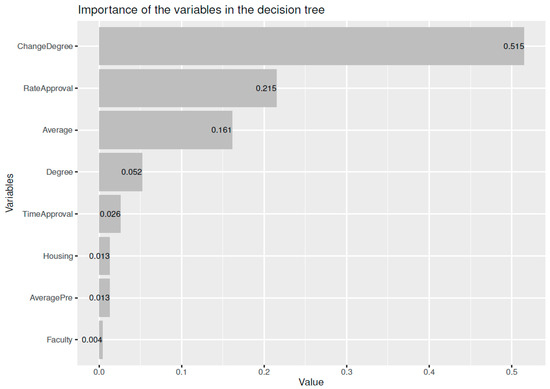
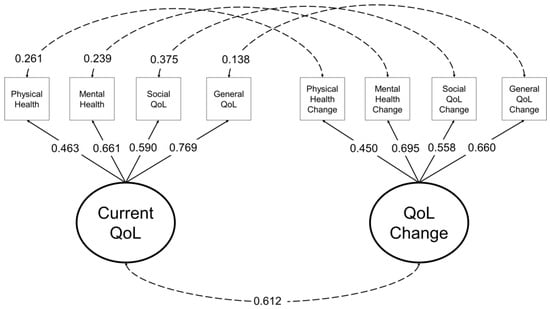
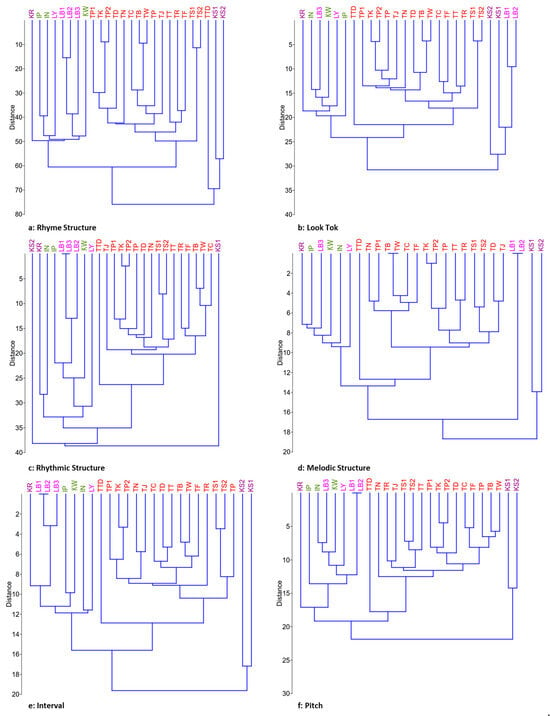
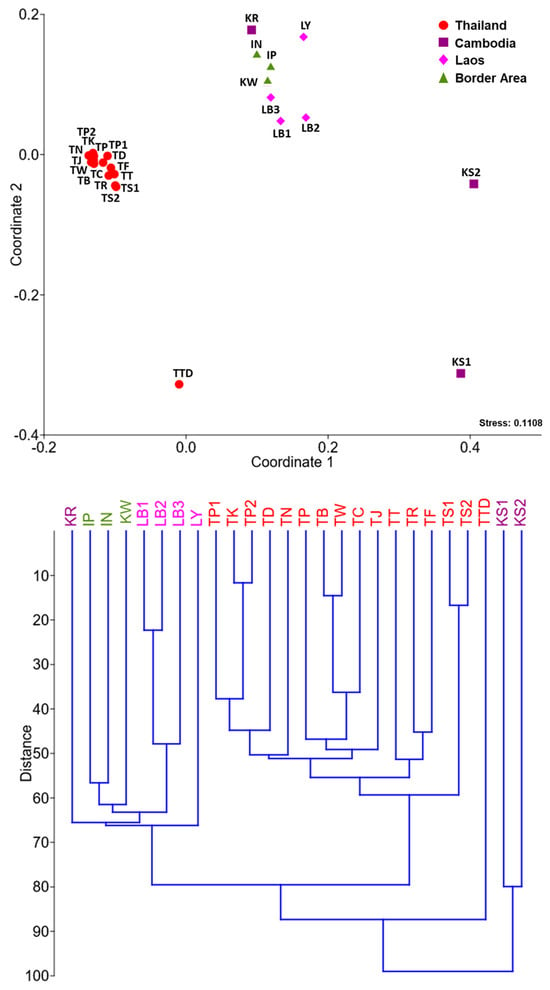
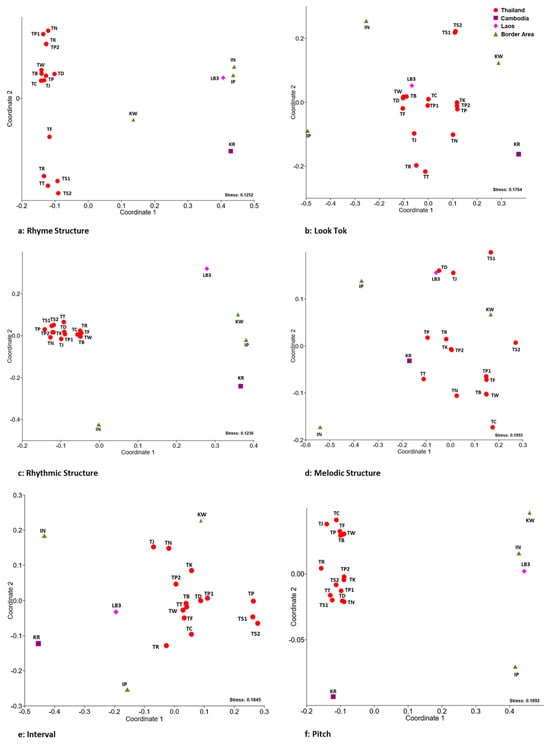
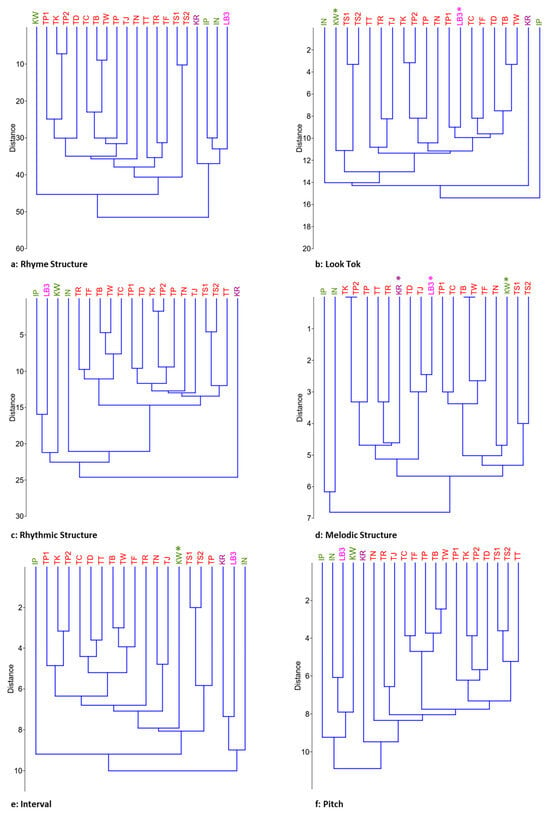
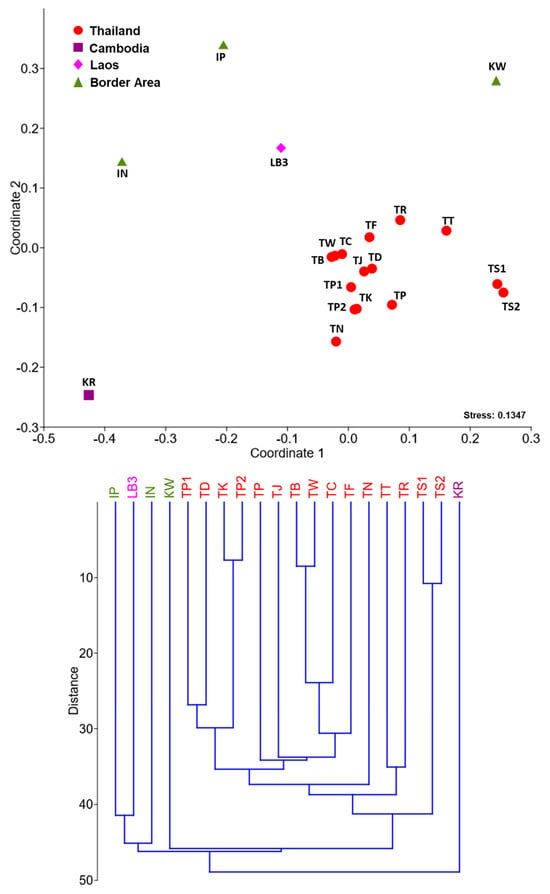
The evaluation and ranking of educational institutions are of paramount importance to a wide range of stakeholders, including students, faculty members, funding organizations, and the institutions themselves. Traditional ranking systems, such as those provided by QS, ARWU, and THE, have offered valuable insights into university performance by employing a variety of indicators to reflect institutional excellence across research, teaching, international outlook, and more. However, these linear rankings may not fully capture the multifaceted nature of university performance. This study introduces a novel clustering analysis that complements existing rankings by grouping universities with similar characteristics, providing a multidimensional perspective on global higher education landscapes. Utilizing a range of clustering algorithms—K-Means, GMM, Agglomerative, and Fuzzy C-Means—and incorporating both traditional and unique indicators, our approach seeks to highlight the commonalities and shared strengths within clusters of universities. This analysis does not aim to supplant existing ranking systems but to augment them by offering stakeholders an alternative lens through which to view and assess university performance. By focusing on group similarities rather than ordinal positions, our method encourages a more nuanced understanding of institutional excellence and facilitates peer learning among universities with similar profiles. While acknowledging the limitations inherent in any methodological approach, including the selection of indicators and clustering algorithms, this study underscores the value of complementary analyses in enriching our understanding of higher educational institutions’ performance.
Full article

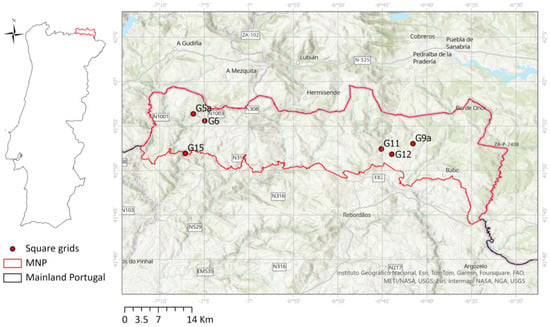
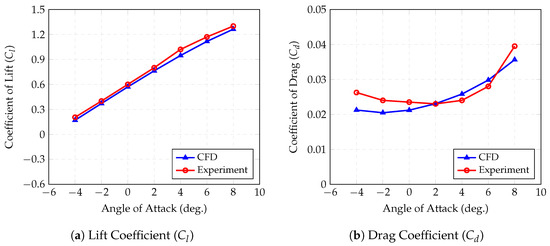
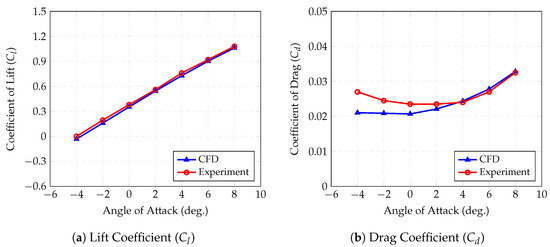
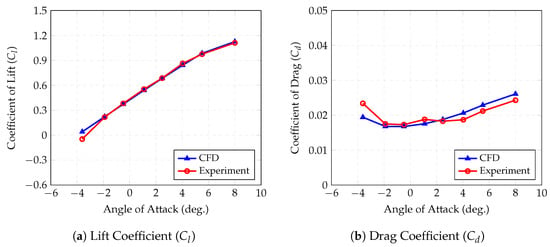
Figure 1







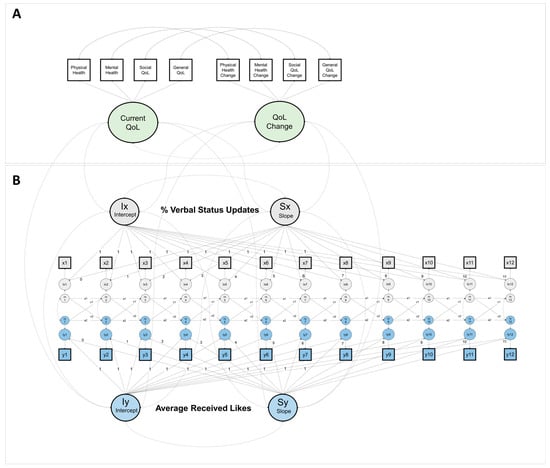
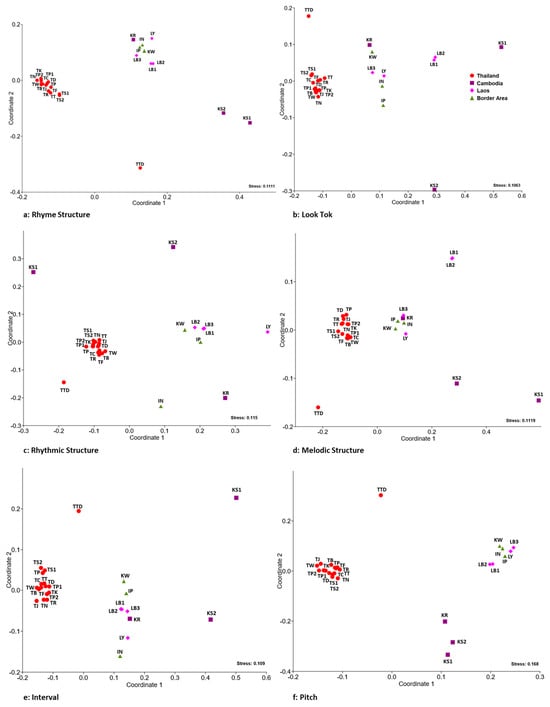



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
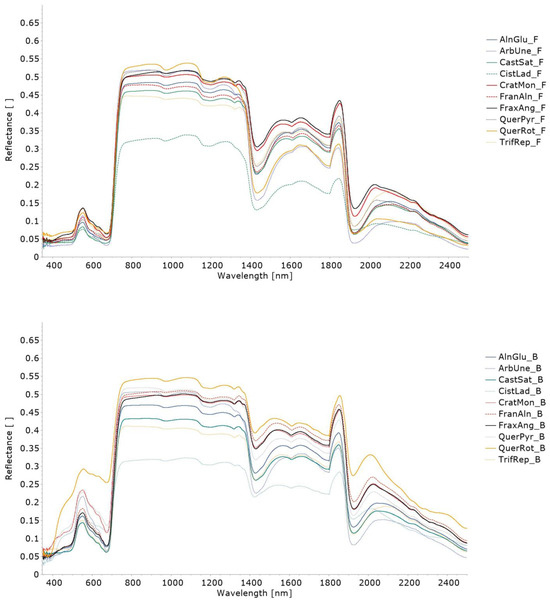{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}